In computer algorithms, there is this thing called ‘soft heap‘, due to Princeton computer scientist Bernard Chazelle (2000), which is basically corrupting a certain percentage of data when building the data structure. When first heard of that, I can’t imagine how on earth could such a thing be anywhere useful.
Indeed it is, and the reason it works is quite interesting to me. Hence I’m writing this post about finding the (real) 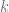
Part 1: Heap
Naively sorting a set (i.e. compare the first two elements, put the smaller first; compare the 2nd and 3rd, move the third past the 2nd if it’s smaller; then compare the 3rd and the first, etc.) could take 

One way to achieve
A heap is a binary tree with a number (key) in each node and the child of a node always has key larger than that of the node. (i.e. the minimum element is at the root)
Now the problem of sorting breaks into two parts:
i) build a heap with our given keys
ii) sort elements in a heap
As we can see, if we manage to build a heap with all branches having roughly the same length (computer scientist call that a balanced binary tree), there will be 

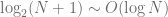

Building the heap: Suppose we already have the first 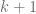

In total, building the heap takes no more than 
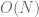
Sort from the heap: Take the root as the minimum element, delete it from the heap; now compare the two elements in level 1, put the smaller into the root, now compare the two children of the empty node, etc. (if at some stage the empty node has only one child then just move it, stop if the empty node has no child.) At the end, delete the leaf node that’s empty. Again this process takes no more than
twice the height of the tree many operations.
Combining the above two steps, we have
As one can guess heaps does much more than sorting stuff, once we spent our time to build data into a heap, we can save such structure and update it once the data set changes:
Inserting element: 
Find minimum: 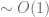
Delete minimum:
OK~ so much for that, let’s move to the more interesting business:
Part 2: Error
The idea is: given a set of data with keys, instead of putting them into a heap, we put them into another structure (i.e. ‘soft heap’) such that the structure assigns a fake key every element and treat it as the real key. It does so in a way that:
i) All elements have fake keys larger than or equal to their real key.
ii) Only a certain percentage (
The advantage of doing that is, unlike heap, it now takes only
Meanwhile, I guess the most curious thing is, how can we get any uncorrupted results with a corrupted data structure? As an example, let’s see how to find the (genuine) medium with data structure having
The mean observation is that, since all fake keys are larger than real keys, by deleting the smallest 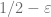
Now we have reduced the problem to finding the 


At each step, we reduce the size of the data set by at least a factor of 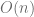

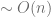
Since the size shrinks in constant factor, the total running time is simply a geometric series, hence 
Remarks:
1. In the above argument, 
2. It doesn’t matter whether we are finding the medium or the 
3. The problem of finding the
